
The one question that tells you if you're ready for AI agents
The question isn't whether you're technical enough for AI agents. It's whether your team already has repeatable work that needs to get done every week.

You don't need an AI strategy. You need one less task.
Every week there's a new AI tool that promises to change everything. If you're running a small business, it's easy to feel like you're already behind.
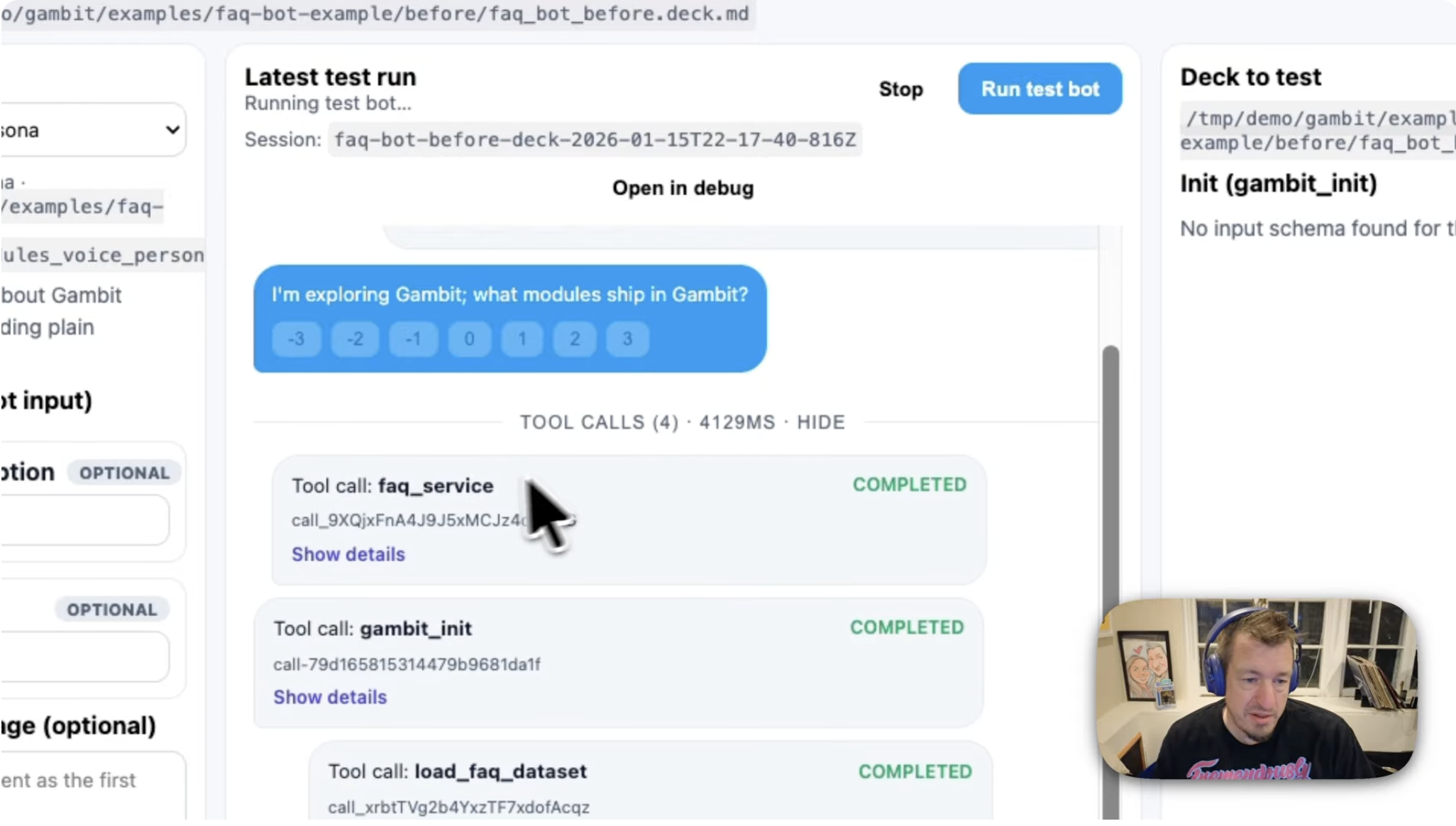
Gambit: a launch-era agent harness for reliable agents, assistants, and workflows
Gambit helps agent teams create synthetic scenarios, validate eval data, grade behavior, and preserve regression evidence without rebuilding orchestration from scratch.

Context engineering is the way
Context engineering is the new term for the work behind reliable LLM systems: systematically optimizing performance through structured samples, graders, and proper information hierarchy.

Evals from scratch: Building LLM evals with aibff from Markdown and TOML
We built a reliable eval system using Markdown, TOML, and a command-line tool that adapts when you change prompts, demonstrated through creating graders for an AI-powered sports newsletter.
From inconsistent outputs to perfect reliability in under an hour
How Velvet increased their citation XML output reliability to 100% in under an hour using LLM attention management principles.

5 things about LLM prompts we think everyone should know
Most teams are building LLM prompts wrong. Here are 5 essential concepts for building reliable LLM applications.